

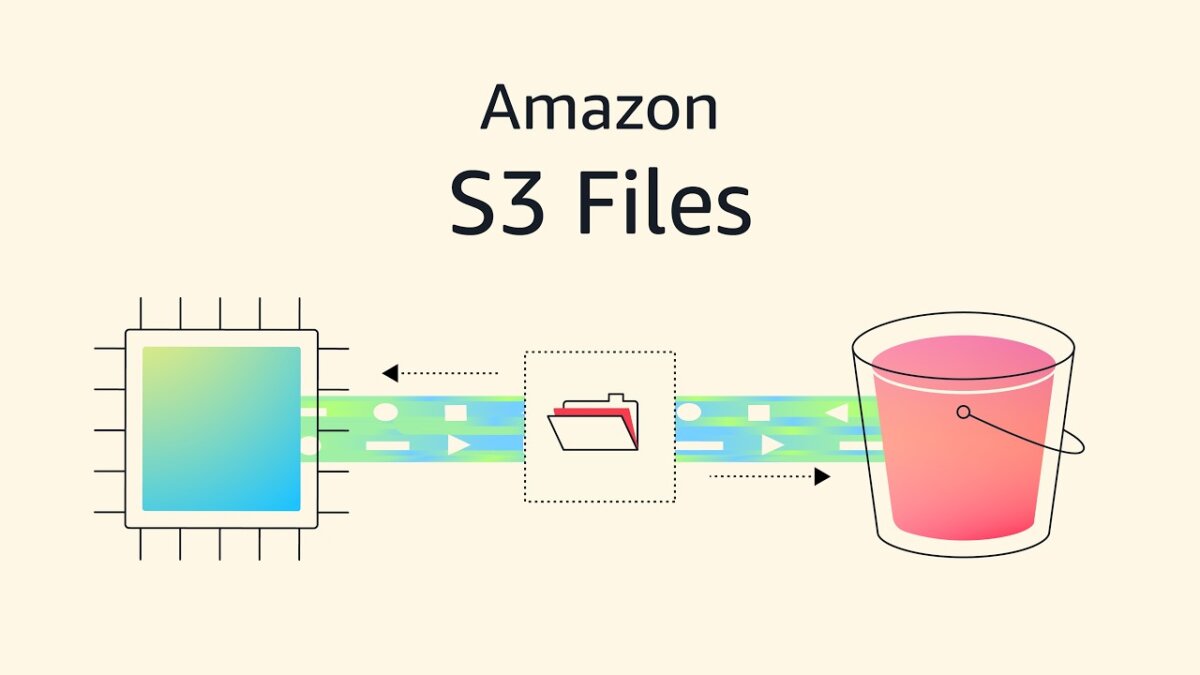
Amazon Web Services has introduced a new capability that bridges one of cloud computing’s longest-standing technical divides, allowing developers and data scientists to access data stored in its S3 cloud storage service as though it were a traditional file system.
The new feature, called Amazon S3 Files, lets applications running on AWS read and write data in S3 storage buckets using standard file operations rather than the specialised cloud storage commands that have defined the service since its launch 20 years ago. In practical terms, a machine learning team can now run a training job directly against data stored in S3 without first copying it to a separate file system, a step that has long added time, complexity, and cost to data workflows. For AI agents, the implications are equally significant, as they can now interact with S3 data using the same basic tools they would use on a local hard drive.
The technical challenge of making this work was significant and, according to AWS, took years to get right. Andy Warfield, a vice president and distinguished engineer who leads S3 engineering at AWS, published an unusually candid account of the development process alongside the announcement. The core problem, Warfield explained, is that files and objects are fundamentally different by design. Files can be edited in place and shared across applications in real time. Objects in S3 are stored and retrieved as complete units, and millions of applications are built around that assumption. Changing either model risked breaking existing systems at massive scale.
The team’s first approach failed. “We did the only sensible thing you can do when you are faced with a really difficult technical design problem: we locked a bunch of our most senior engineers in a room and not let them out till they had a plan that they all liked,” Warfield wrote. “Passionate and contentious discussions ensued,” he added. “And then finally we gave up.”
The solution the team eventually landed on stopped trying to hide the boundary between files and objects and instead made it a central part of the design. S3 Files uses a stage and commit model borrowed from version control systems like Git, where changes accumulate on the file system side and are pushed back to S3 as complete objects, preserving the guarantees that existing S3 applications depend on.
Google and Microsoft both offer tools for accessing cloud object storage through file system interfaces, but AWS is positioning S3 Files as a deeper integration backed by a fully managed file system rather than a simple adapter. The feature is built on Amazon’s Elastic File System and is available today across AWS regions worldwide. The company said it has been in customer testing for approximately nine months.



{kind=link}